传统神经网络的局限性
- 输入输出固定
- 计算步骤固定
- 层数固定,每次处理都走一遍计算图
- 不具备处理任意长度输入序列的能力
引入 RNN 一个有趣案例
如何设计一个循环网络检测重复的
1
输入序列:X = [0, 1, 0, 1, 1, 1, 0, 1, 1] 目标输出:Y = [0, 0, 0, 0,
1, 1, 0, 0, 1] 
具体设计要点
- 隐藏状态 ht 设计为:
- 每一步计算需要记录当前输入到 current, 上一时间步的 current 输入到
previous, 偏置为 1
于是
Why = [1, 1, −1]
然后 Why 和
ht
相乘再经过 ReLU 变换,即可实现要求
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import numpy as np
h_0 = np.array([[0], [0], [1]])
w_xh = np.array([[1], [0], [0]])
w_hh = np.array([
[0, 0, 0],
[1, 0, 0],
[0, 0, 1]
])
w_yh = np.array([1, 1, -1])
x_in = [0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1]
x_seq = np.array([[x] for x in x_in])
h_t_prev = h_0
def relu(x):
return np.maximum(0, x)
y_seq = []
for t, x in enumerate(x_seq):
h_t = relu(w_hh @ h_t_prev + (w_xh @ x).reshape(3,1))
y_t = relu(w_yh @ h_t)
y_seq.append(y_t)
h_t_prev = h_t
print("Inputs: ", [int(x) for x in x_seq.flatten()])
print("Outputs:", [int(y[0]) for y in y_seq])
|
RNN 的优势
- 能处理变长的序列(输入输出均可变长)
- 一个时间步一个计算单元,不是增加网络层,而是增加时间步
- 每一步的计算共享权重,可无限展开
- 相当于用同一个“程序块”在时间上不断迭代执行
- 时间维度的”深度”是动态的,而不是结构上死板的堆层数
- 从函数式学习走向“可微程序设计”
If training vanilla neural nets is optimization over functions,
training recurrent nets is optimization over programs.
RNN 的结构
运作原理
RNN
主要由输入层、隐藏层和输出层组成,其中隐藏层会在每个时间步(t)维护一个隐藏状态
ht :
ht = f(Whht − 1 + Wxxt + b)
yt = g(Wyht + by)
(注意这是简单循环网络,也称 Elman 网络, 还有 jordan 网络)
 image.png
image.png
pytorch 前向传播代码
注意 pytorch 将循环步骤封装到了 nn. RNN 模块里了,具体实现参照原码和
cs231n 作业
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import torch
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
out = self.fc(out[:, -1, :])
return out
input_size = 10
hidden_size = 20
output_size = 1
model = SimpleRNN(input_size, hidden_size, output_size)
x = torch.randn(5, 3, 10)
output = model(x)
print(output.shape)
|
种类
many to many
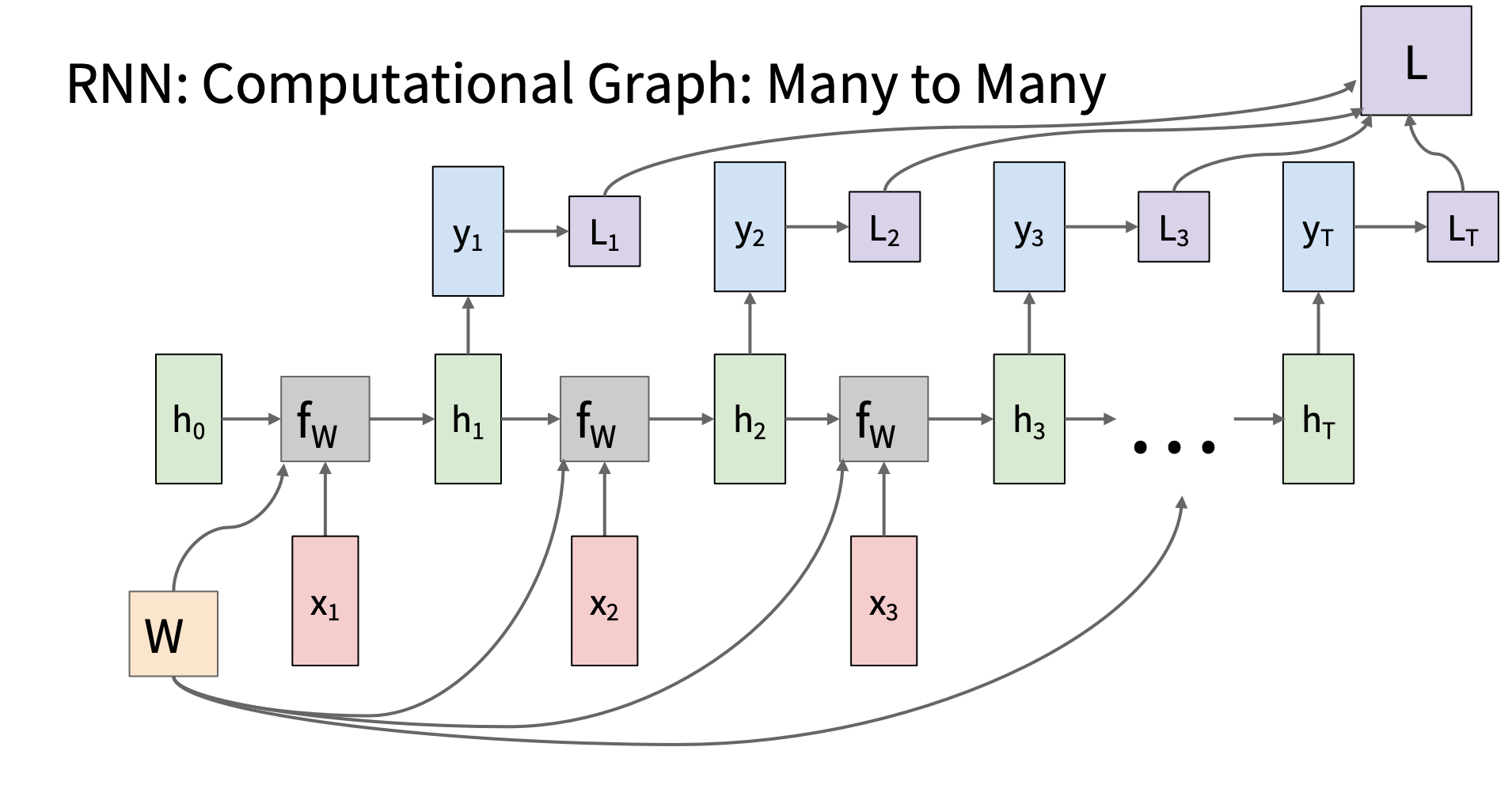 image.png
image.png
| 应用 |
输入序列 |
输出序列 |
例子 |
| 语音识别 |
音频帧序列 |
字符或单词序列 |
语音 → 文本 |
| 机器翻译 |
源语言句子 |
目标语言句子 |
English → 中文 |
| 视频字幕生成 |
视频帧序列 |
描述词语序列 |
视频 → 字幕 |
| 音乐生成 |
前面几个音符 |
后面音符 |
连续旋律生成 |
大致流程:训练+推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| import torch
import torch.nn as nn
import torch.nn.functional as F
class RNNLanguageModel(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.RNN(embed_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, vocab_size)
self.hidden_size = hidden_size
def forward(self, x, hidden=None):
"""
前向传播(用于训练):
x: (batch_size, seq_len) --> 输入词 id 序列
返回: (batch_size, seq_len, vocab_size)
"""
emb = self.embedding(x)
if hidden is None:
hidden = torch.zeros(1, x.size(0), self.hidden_size, device=x.device)
out, _ = self.rnn(emb, hidden)
logits = self.fc(out)
return logits
def generate(self, start_token_id, end_token_id, max_len=20, device='cpu'):
"""
推理生成函数:逐步生成序列直到遇到 <END>
返回:生成的 token id 序列(包含 START,不包含 END)
"""
self.eval()
input_id = torch.tensor([[start_token_id]], device=device)
hidden = torch.zeros(1, 1, self.hidden_size, device=device)
generated_ids = [start_token_id]
for _ in range(max_len):
emb = self.embedding(input_id)
out, hidden = self.rnn(emb, hidden)
logits = self.fc(out.squeeze(1))
probs = F.softmax(logits, dim=-1)
next_id = torch.argmax(probs, dim=-1).item()
if next_id == end_token_id:
break
generated_ids.append(next_id)
input_id = torch.tensor([[next_id]], device=device)
return generated_ids
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
vocab = {"<START>": 0, "<END>": 1, "hello": 2, "world": 3}
inv_vocab = {v: k for k, v in vocab.items()}
vocab_size = len(vocab)
model = RNNLanguageModel(vocab_size, embed_size=32, hidden_size=64)
x = torch.tensor([[0, 2, 3]])
target = torch.tensor([[2, 3, 1]])
logits = model(x)
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(logits.view(-1, vocab_size), target.view(-1))
loss.backward()
generated_ids = model.generate(start_token_id=vocab["<START>"],
end_token_id=vocab["<END>"],
max_len=10)
generated_tokens = [inv_vocab[i] for i in generated_ids]
print("Generated:", generated_tokens)
|
many to one
-
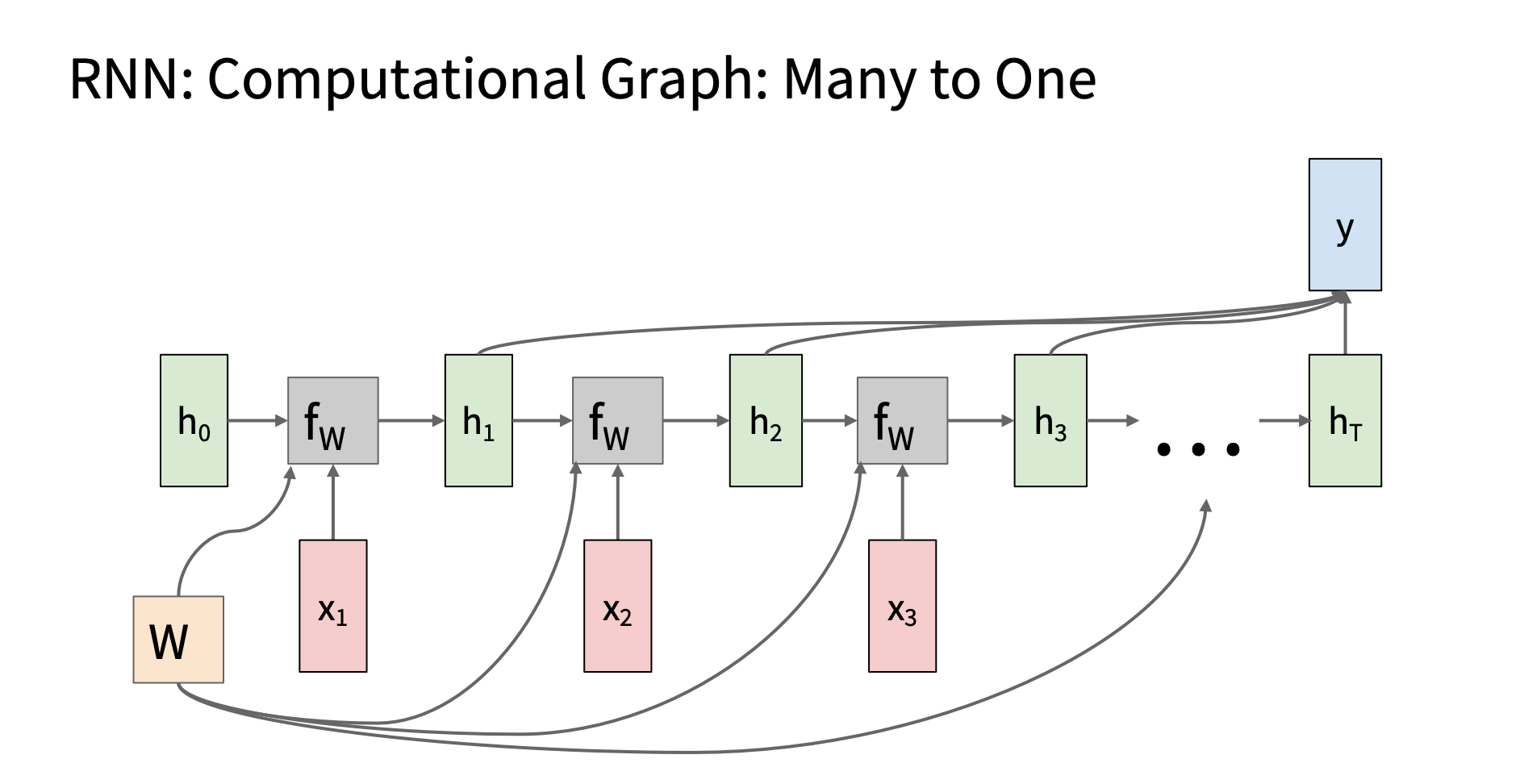 image.png
image.png
应用
| 应用 |
输入序列 |
输出单值 |
| 情感分类 |
一段评论(多个词) |
情绪是正向 / 负向 |
| 问题分类 |
一个问题的文本 |
问题类别 |
| 股票预测 |
一段时间的价格序列 |
下一日涨/跌 |
| 语音命令识别 |
音频帧序列 |
命令类型(如“打开灯”) |
代码 与上面 many to many 类似,只用改一行 将
1
2
3
4
5
| def forward(self, x):
out, _ = self.rnn(x)
logits = self.fc(out)
return logits
|
改成
1
2
3
4
5
6
| def forward(self, x):
out, _ = self.rnn(x)
last = out[:, -1, :]
logits = self.fc(last)
return logits
|
注意可以用 flag 控制,选择不同 rnn 种类,类似 cs231n assignment2
那样
one to many
一般在推理时用,代码框架见下面的decoder.。训练阶段通常是
teacherforcing, 类似many-to-many 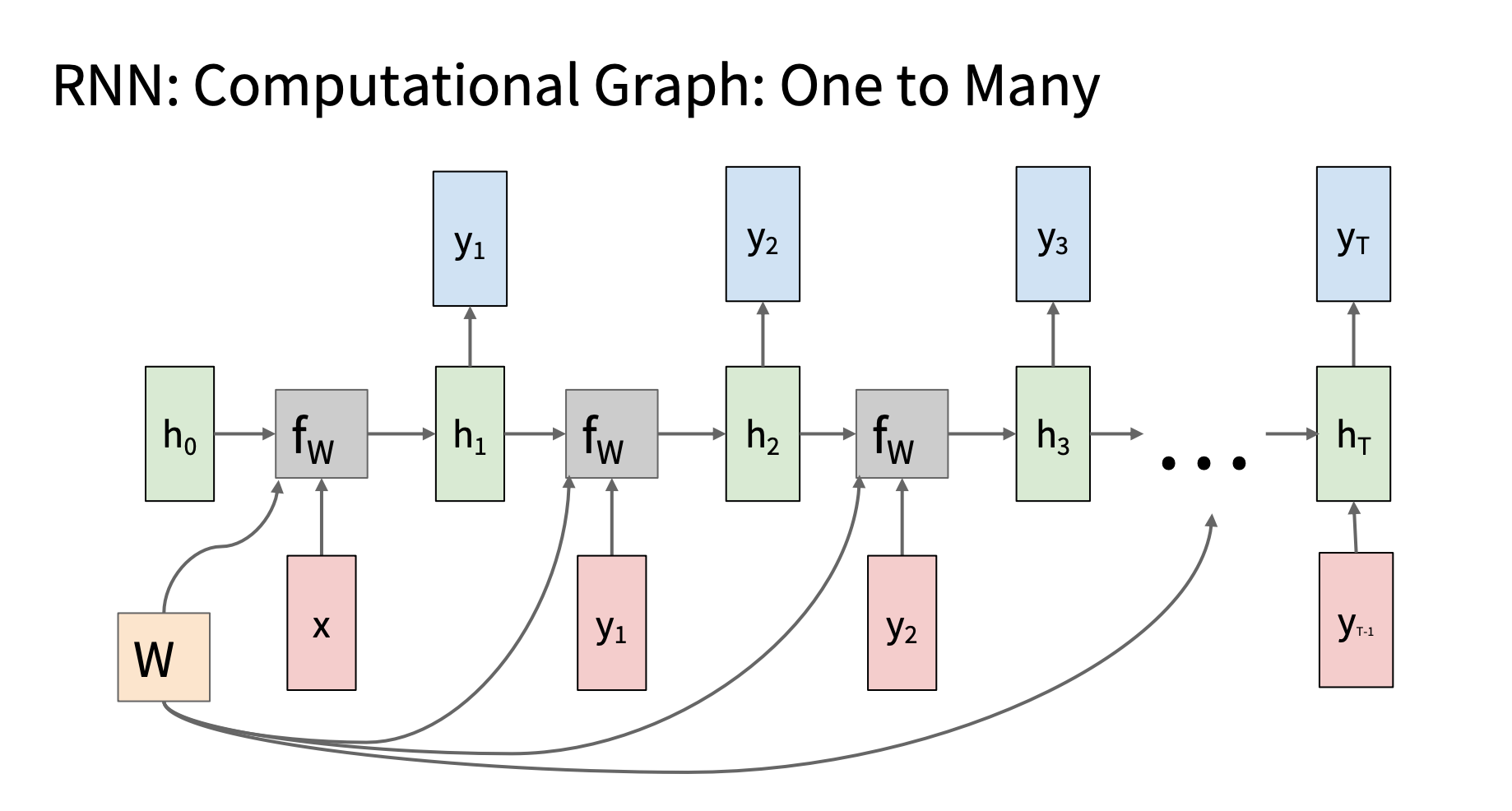
| 场景 |
输入 |
输出 |
| 图像字幕生成 |
图像特征向量 |
单词序列描述 |
| 音频生成 |
起始音频帧或噪声向量 |
完整音频序列 |
| 文本生成(从 prompt) |
一个初始 token |
多个生成词 |
| 编码器-解码器中的解码器 |
上一步 hidden 或 |
多个 y |
Seq2Seq (Many-to-One +
One-to-Many)
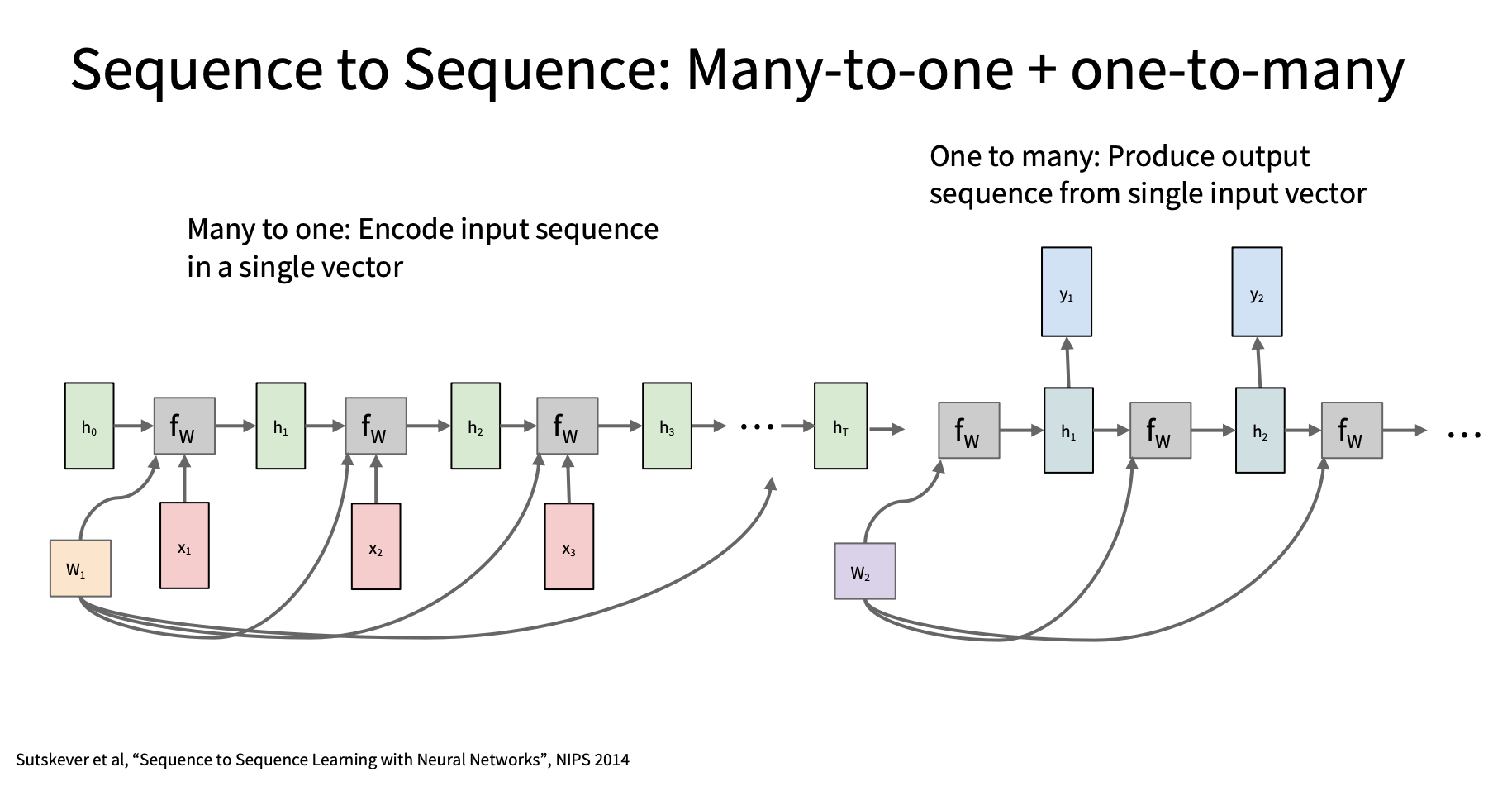 image.png
image.png
应用场景 机器翻译,语音识别, 图像字幕生成, 对话系统
,语音识别,文本生成(摘要/诗歌)
代码框架示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| import torch
import torch.nn as nn
import random
class Encoder(nn.Module):
def __init__(self, input_vocab_size, embed_size, hidden_size):
super().__init__()
self.embedding = nn.Embedding(input_vocab_size, embed_size)
self.rnn = nn.RNN(embed_size, hidden_size, batch_first=True)
def forward(self, src):
embedded = self.embedding(src)
_, hidden = self.rnn(embedded)
return hidden
class Decoder(nn.Module):
def __init__(self, output_vocab_size, embed_size, hidden_size):
super().__init__()
self.embedding = nn.Embedding(output_vocab_size, embed_size)
self.rnn = nn.RNN(embed_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_vocab_size)
def forward(self, input_token, hidden):
embedded = self.embedding(input_token)
output, hidden = self.rnn(embedded, hidden)
logits = self.fc(output)
return logits, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
"""
src: (B, T_src), tgt: (B, T_tgt)
返回: logits: (B, T_tgt, vocab_size)
"""
batch_size, tgt_len = tgt.shape
vocab_size = self.decoder.fc.out_features
logits = torch.zeros(batch_size, tgt_len, vocab_size).to(self.device)
hidden = self.encoder(src)
input_token = tgt[:, 0].unsqueeze(1)
for t in range(1, tgt_len):
output, hidden = self.decoder(input_token, hidden)
logits[:, t] = output.squeeze(1)
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(2)
input_token = tgt[:, t].unsqueeze(1) if teacher_force else top1
return logits
def generate(self, src, start_token, end_token, max_len=20):
self.eval()
hidden = self.encoder(src.to(self.device))
input_token = torch.tensor([[start_token]], device=self.device)
output_tokens = []
for _ in range(max_len):
output, hidden = self.decoder(input_token, hidden)
next_token = output.argmax(2).item()
if next_token == end_token:
break
output_tokens.append(next_token)
input_token = torch.tensor([[next_token]], device=self.device)
return output_tokens
|
调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
INPUT_VOCAB_SIZE = 1000
OUTPUT_VOCAB_SIZE = 1000
EMBED_SIZE = 128
HIDDEN_SIZE = 256
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
encoder = Encoder(INPUT_VOCAB_SIZE, EMBED_SIZE, HIDDEN_SIZE)
decoder = Decoder(OUTPUT_VOCAB_SIZE, EMBED_SIZE, HIDDEN_SIZE)
model = Seq2Seq(encoder, decoder, device=DEVICE).to(DEVICE)
src = torch.randint(0, 1000, (32, 10)).to(DEVICE)
tgt = torch.randint(0, 1000, (32, 12)).to(DEVICE)
logits = model(src, tgt, teacher_forcing_ratio=0.7)
start_token = 2
end_token = 3
src_one = torch.randint(0, 1000, (1, 10)).to(DEVICE)
result = model.generate(src_one, start_token, end_token)
print(result)
|
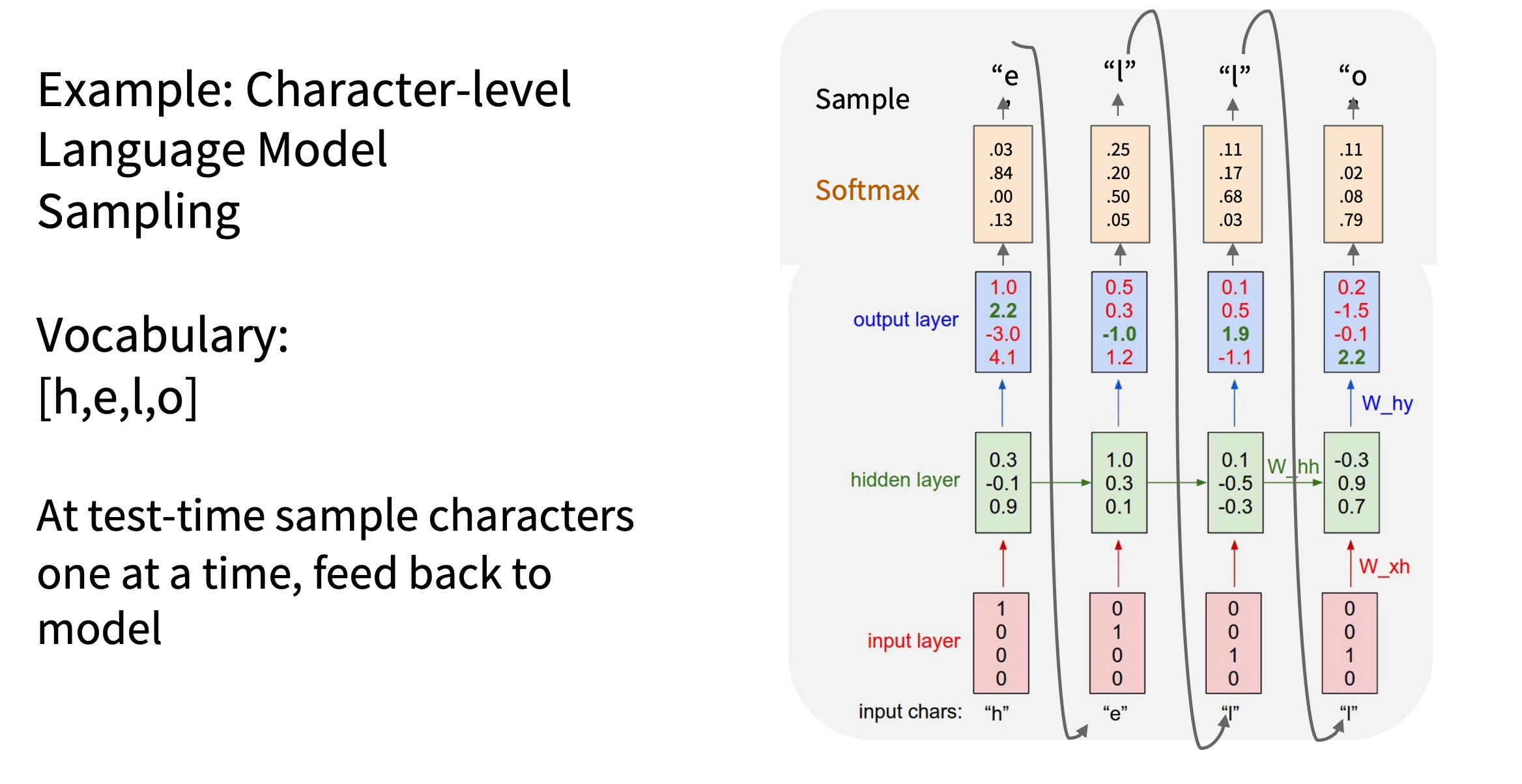
采样
RNN 是字符级语言模型(Character-level Language
Model),推理过程中进行采样,增加输出多样性
如图,这里并没按照最大得分作为输出,而是进行了采样
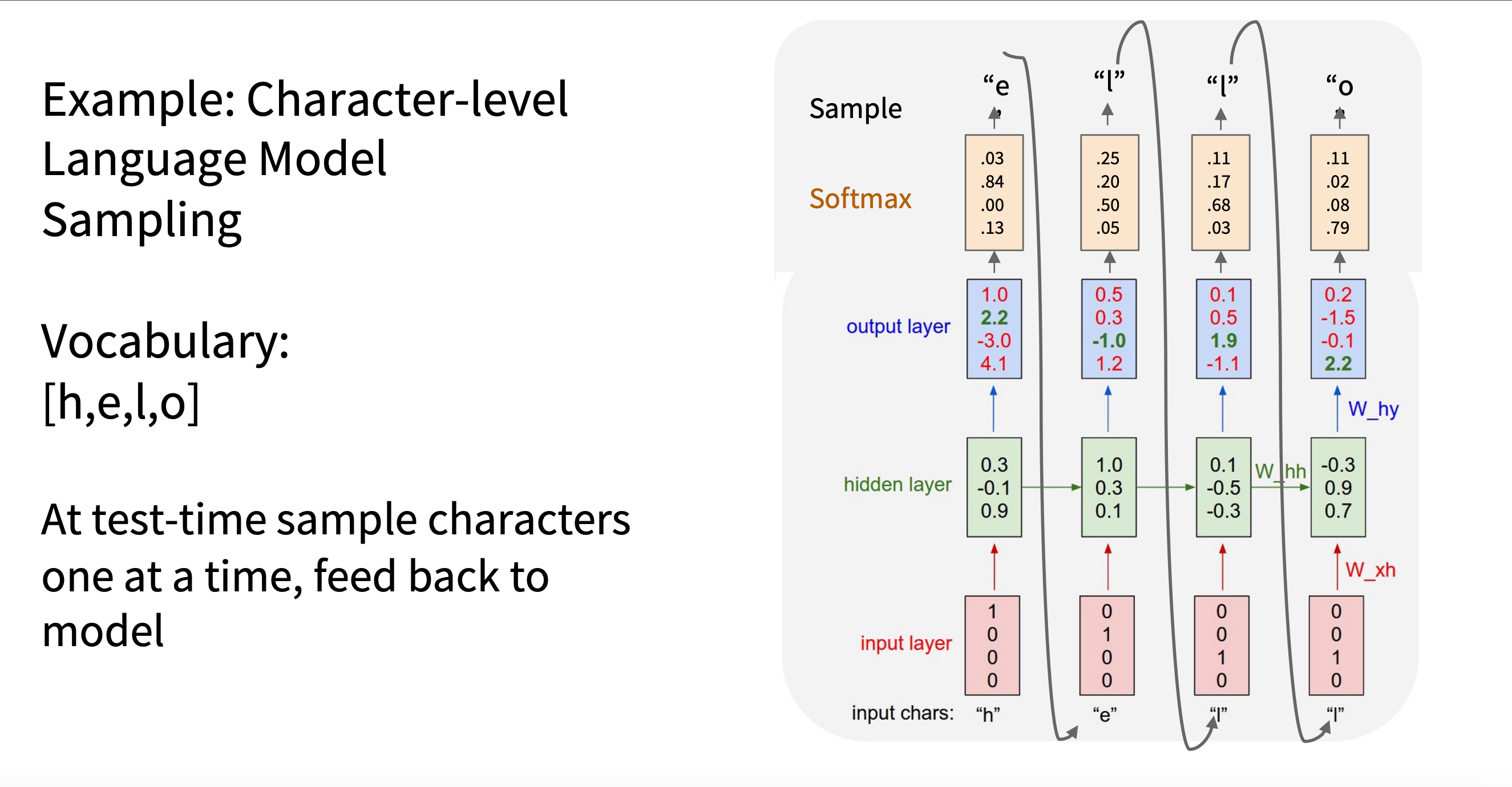 image.png
image.png
| 阶段 |
是否采样 |
是否可微 |
用途 |
| 训练 |
不采样,用真实标签 |
可微分 |
用于学习参数 |
| 测试/生成 |
采样(或 argmax) |
不可微 |
用于生成新文本 |
| 高级方法(Gumbel、REINFORCE) |
近似采样 |
近似可微 |
特殊任务下尝试采样训练 |
测试阶段是否采样取决于任务的类型,若是翻译类型,则要求准确性;若为生成更丰富和多样化的文本时,比如文本生成(如
GPT 生成对话)、诗歌创作、自动写作等任务, 则要采样
贪心搜索
1
| next_token = torch.argmax(logits, dim=-1)
|
- 优点:简单,确定性强。
- 缺点:容易陷入平庸、重复,缺乏多样性。
随机采样
1
2
| probs = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
|
- 优点:多样性高。
- 缺点:可能采样出不合理的词,导致生成质量差。
温度采样
在实际应用中,采样时可以引入温度参数(temperature)来控制采样的随机性:
- 高温度 T >
1:增加探索性,生成更加随机和多样的文本。
- 低温度 T < 1:减少随机性,更接近
argmax,但仍保留一定的随机性。
- T=0.1 → 选择最高概率的单词(接近 argmax)
- T=1.0 → 典型的采样
- T=2.0 → 允许更多低概率的单词被选中(更加随机)
1
2
3
4
| temperature = 0.7
probs = torch.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
|
Top-k 采样
- 原理:每次只在概率最高的 k
个词中进行随机采样。
1
2
3
4
5
| k = 10
topk_probs, topk_indices = torch.topk(logits, k)
probs = torch.softmax(topk_probs, dim=-1)
next_token = topk_indices.gather(-1, torch.multinomial(probs, 1))
|
- 优点:避免随机性过大,平衡多样性和合理性。
- 缺点:固定 k 可能忽略尾部重要词。
Top-p 采样(Nucleus Sampling)
- 原理:动态选择累计概率 ≥ p
的词汇子集进行采样。
- 常用 p 值:0.8 ~ 0.95
1
2
3
4
5
6
7
8
9
10
11
12
13
| p = 0.9
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.softmax(sorted_logits, dim=-1).cumsum(dim=-1)
mask = cumulative_probs > p
mask[..., 1:] = mask[..., :-1].clone()
mask[..., 0] = 0
filtered_logits = sorted_logits.masked_fill(mask, float('-inf'))
probs = torch.softmax(filtered_logits, dim=-1)
next_token = sorted_indices.gather(-1, torch.multinomial(probs, 1))
|
- 优点:自适应词汇量,兼顾多样性和合理性,效果优于
Top-k。
传统one-hot 编码 VS
Embedding
one-hot 编码
特点:
- 高维稀疏:浪费内存和计算资源。
- 只是一种索引方式,没法表达词与词之间的语义关系。
- 适合小词表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import torch
vocab_size = 5
hidden_size = 4
one_hot_input = torch.tensor([[0, 1, 0, 0, 0]], dtype=torch.float)
W_xh = torch.randn(vocab_size, hidden_size)
hidden = one_hot_input @ W_xh
|
加入 embedding
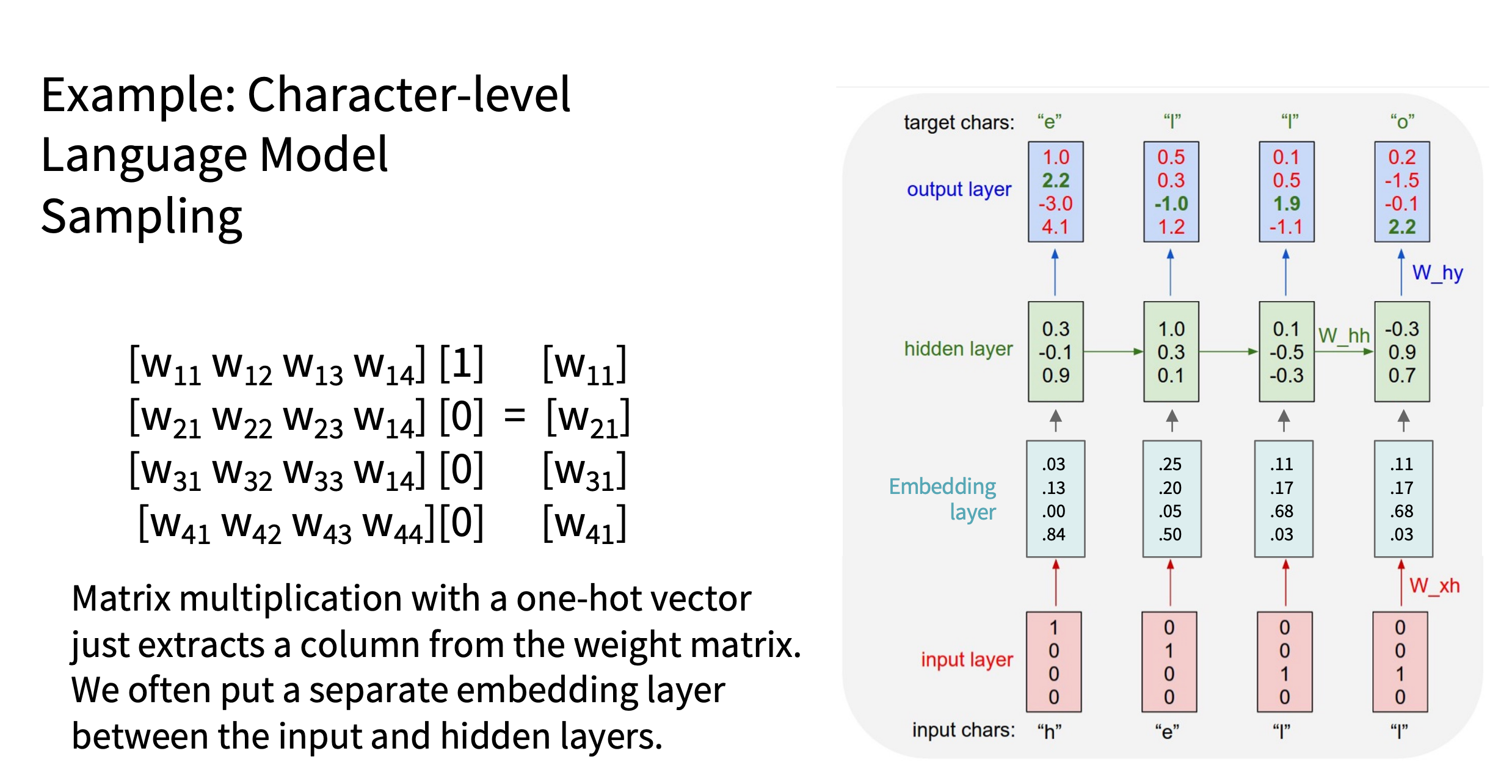 image.png
image.png
原理:
- 每个词对应一个低维稠密向量(embedding lookup 查表机制)。
- 用 nn.Embedding 自动完成映射,相当于查表操作。
- 维度 = 自定义的 embedding size(远小于词表大小)。
内部原理
1
2
| embedding_weight = torch.randn(vocab_size, embed_size)
output = embedding_weight[index]
|
示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
| import torch
import torch.nn as nn
vocab_size = 5
embed_size = 3
embedding = nn.Embedding(vocab_size, embed_size)
input_idx = torch.tensor([1])
embed_vector = embedding(input_idx)
|
Backward
BPTT(Backpropagation Through
Time)
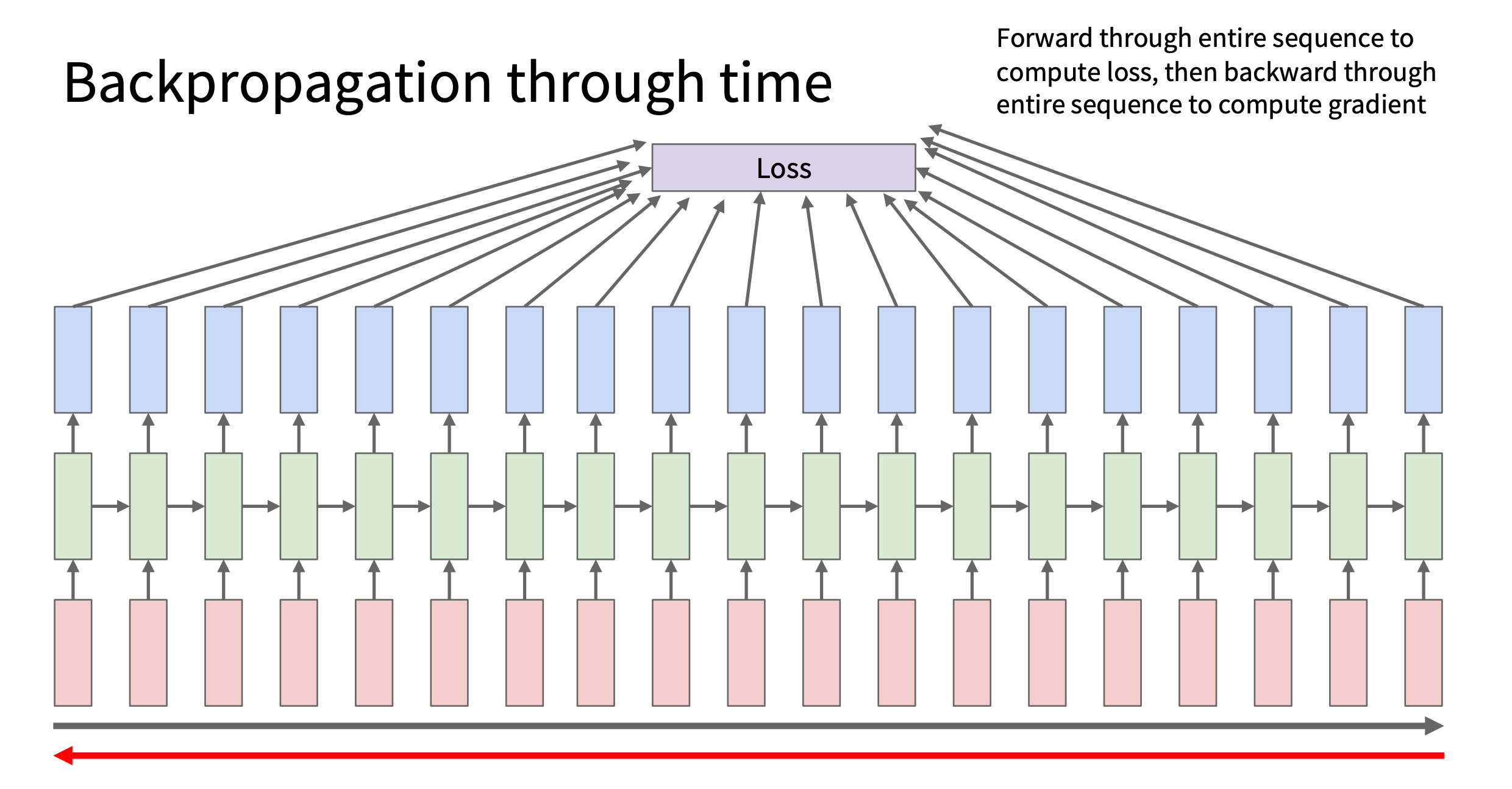 image.png
image.png
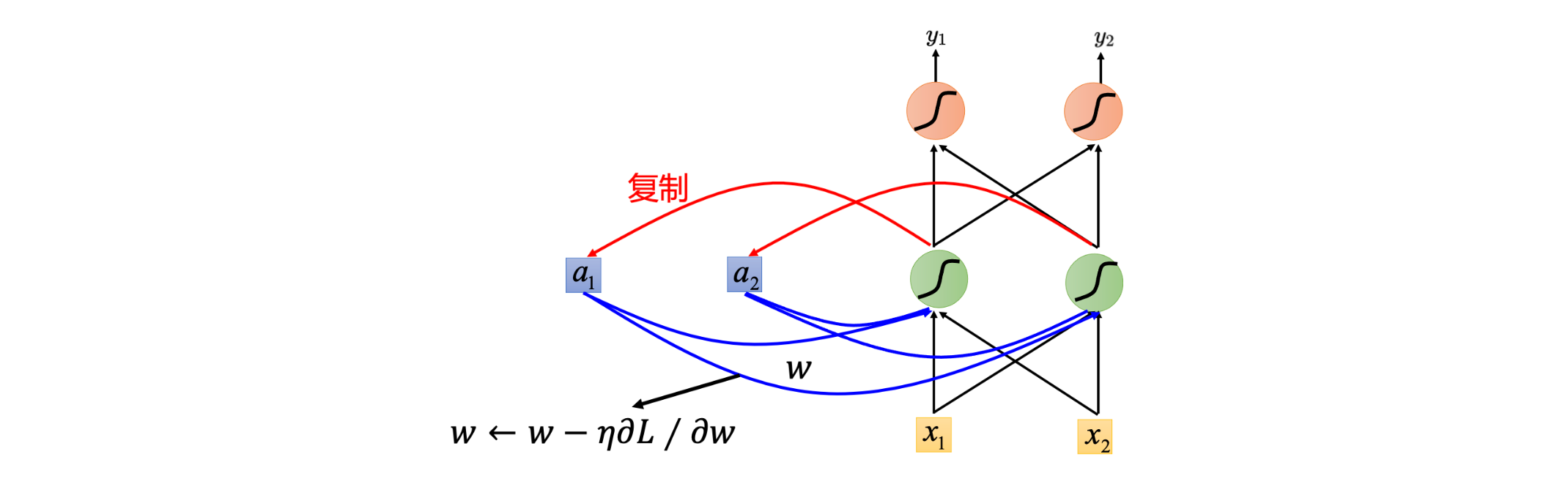 image.png
image.png
因为 Whh 、
Wxh 、
Why
在所有时间步共享,每个时间步的梯度都会累加到同一套参数上
即先积累梯度
再统一进行一次参数更新
对应该步骤的代码
1
2
3
4
5
6
7
8
| optimizer = optim.Adam(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
loss = criterion(outputs.view(-1, output_size), target.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
|
问题 - 计算量大:长序列下效率低,显存消耗巨大。 -
容易出现 梯度消失 / 爆炸 问题。
Truncated BPTT
原理: 假设序列总长 T,我们选择一个截断长度
k,那么:
- 每次前向传播:处理 k 个时间步
- 每次反向传播:只计算这 k 步的梯度
- 隐藏状态 h 会继续传递,但计算图会被“截断”
- 隐藏状态 ht
在时间上传递,模型依然可以“记住”长期信息
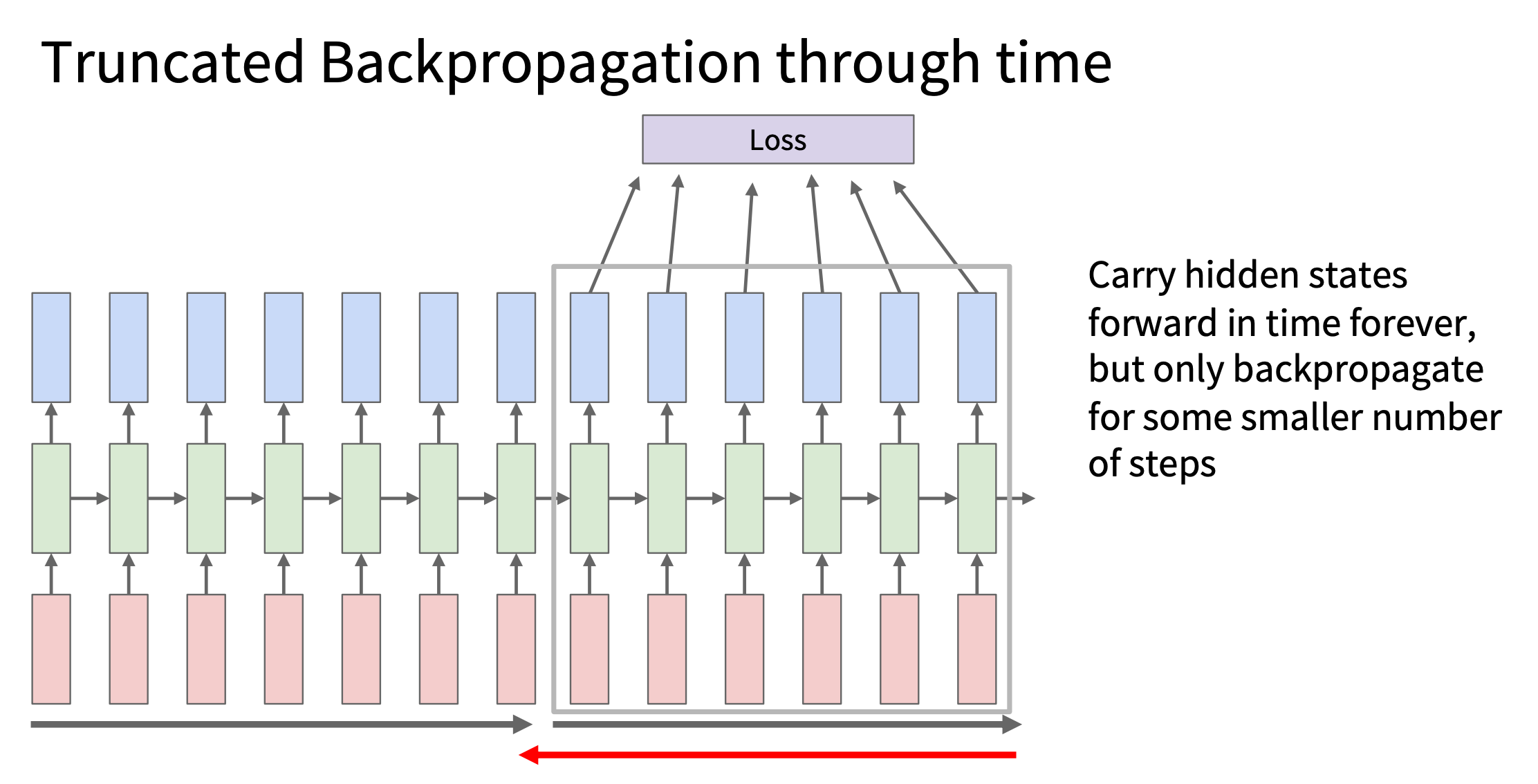 image.png
image.png
计算流程:
- 对于第一个块:t = 1 到 k
更新权重。
- 然后继续下一个块:t = k+1 到 2k
再次更新权重。
相关的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| seq_len = 100
truncation_len = 20
for i in range(0, seq_len, truncation_len):
x_chunk = data[:, i:i+truncation_len, :]
y_chunk = target[:, i:i+truncation_len, :]
output, hidden = model(x_chunk, hidden)
loss = criterion(output, y_chunk)
optimizer.zero_grad()
loss.backward()
hidden = hidden.detach()
optimizer.step()
print(f"Step {i//truncation_len + 1}, Loss: {loss.item():.4f}")
|
测试阶段 softmax
向量还是one-hot 向量
- 训练 vs. 测试的一致性
- 训练时输入的是 one-hot 向量(稀疏的),而 softmax
向量是密集的概率分布
- 模型在训练时并没有学习如何处理 softmax 向量输入
- 输入分布的变化可能导致网络行为不可预测,输出垃圾结果
- 计算复杂性
假设词汇量很大,比如 10,000 个单词,如果我们在测试时输入 softmax
概率向量:
- 每一步输入是一个长度 10,000 的 dense(密集)向量,而不是一个one-hot
稀疏向量(其中只有一个非零值)。
- 计算负担:神经网络的权重矩阵需要和这个 dense
向量相乘,这会显著增加计算复杂性。
- 存储问题:神经网络通常使用稀疏矩阵优化(sparse tensor
operations),one-hot 只需索引操作(见上面 Embedding),而 softmax
向量则需要完整存储和计算。
计算效率和内存管理也是测试时仍然使用 one-hot 关键原因。
- 使用 softmax 向量场景
尽管一般来说测试时使用 one-hot,但在一些特定的情况下,输入 softmax
向量可能有用
- 温度采样(Temperature Sampling):
- 通过 softmax
概率对字符进行采样,而不是总是选择最高概率的字符(argmax)。
- 这样可以生成更加多样化的文本,而不是固定模式的输出。
- 连续 softmax 分布输入(Soft Sampling):
- 在一些高级模型(如自回归变分自动编码器,Auto-Regressive
VAE)中,可能使用 softmax
向量的插值,以产生更平滑的序列转换。
- 神经机器翻译中的 Beam Search:
- 可能在候选词之间进行概率混合,但最终仍然会选择一个确定的词,而不是直接将
softmax 向量输入到下一个时间步。
图像字幕生成(Image
Captioning) 任务的架构
课程中的方法
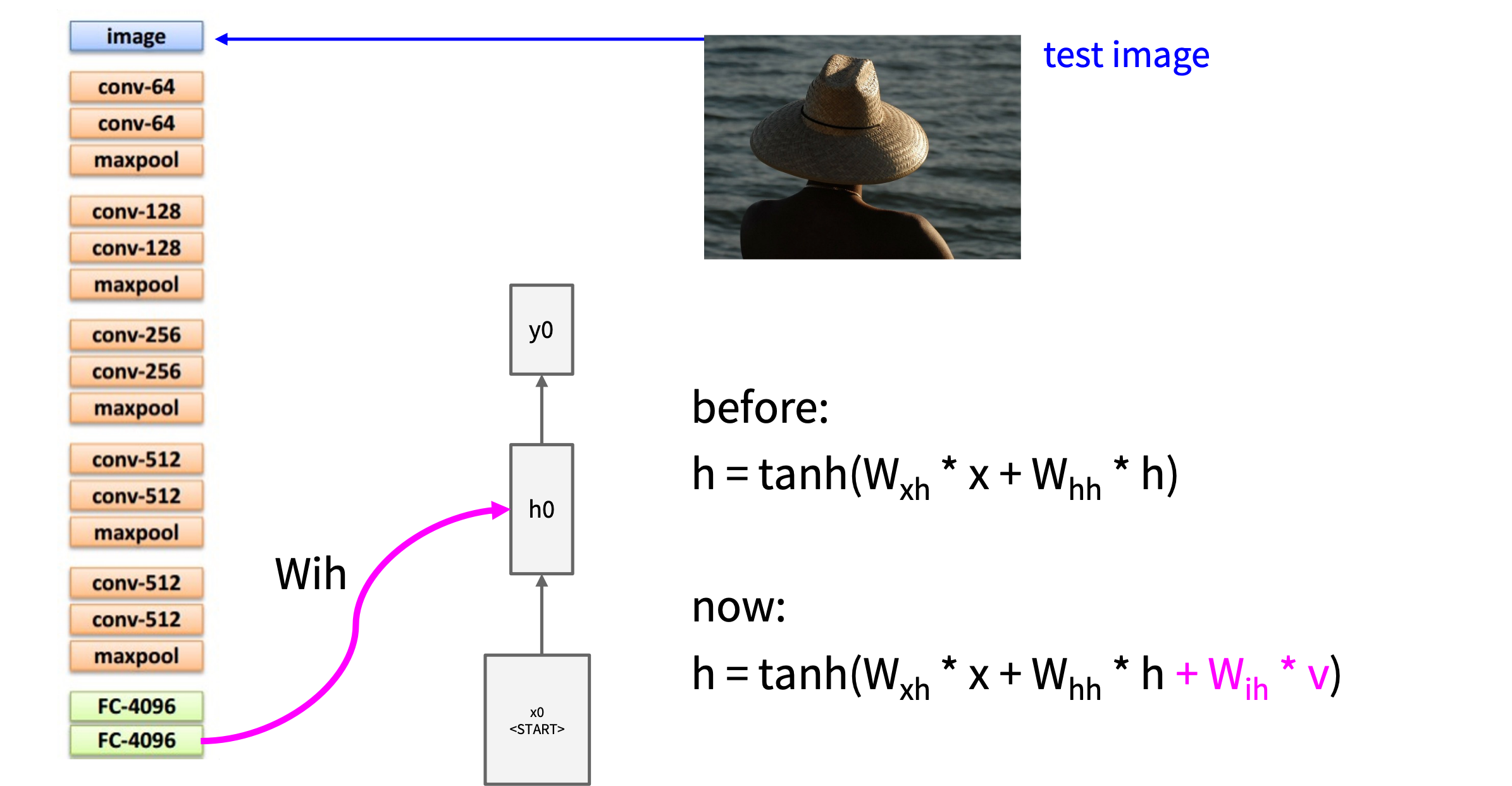 image.png
image.png
更多细节见作业
改进的 RNN 公式如下:
h = tanh (Wxh ⋅ x + Whh ⋅ h + Wih ⋅ v)
每一个时间步引入图像特征, Wih
主要有两个作用:
(1) 让图像信息在整个文本生成过程中持续发挥作用
(2) 让图像信息有独立的学习路径
- 文本输入 x 和图像信息 v
具有不同的特征空间:
- 文本是离散数据(词嵌入),通常来自 NLP 任务(如
Word2Vec、BERT)。
- 图像是连续数据,通常来自 CNN(如
ResNet、VGG)。
- 如果直接用同一个权重矩阵 Wxh
处理两者,可能会导致信息混杂,学习效果下降。
- 引入单独的 Wih
可以让模型独立学习图像信息对文本生成的影响,提高文本的连贯性和语义一致性。
后来的改进
- CNN 负责提取图像特征(VGG、ResNet),并通过 Wih
结合 RNN。
- RNN 负责生成文本,在每个时间步使用 Wih ⋅ v
让图像信息持续影响生成过程。
- 改进方法:后续引入了
注意力机制(Attention),动态调整不同时间步对图像区域的关注程度,而不是使用全局
Wih
。
VQA (视觉问答)
也是经典的 cnn+rnn 架构
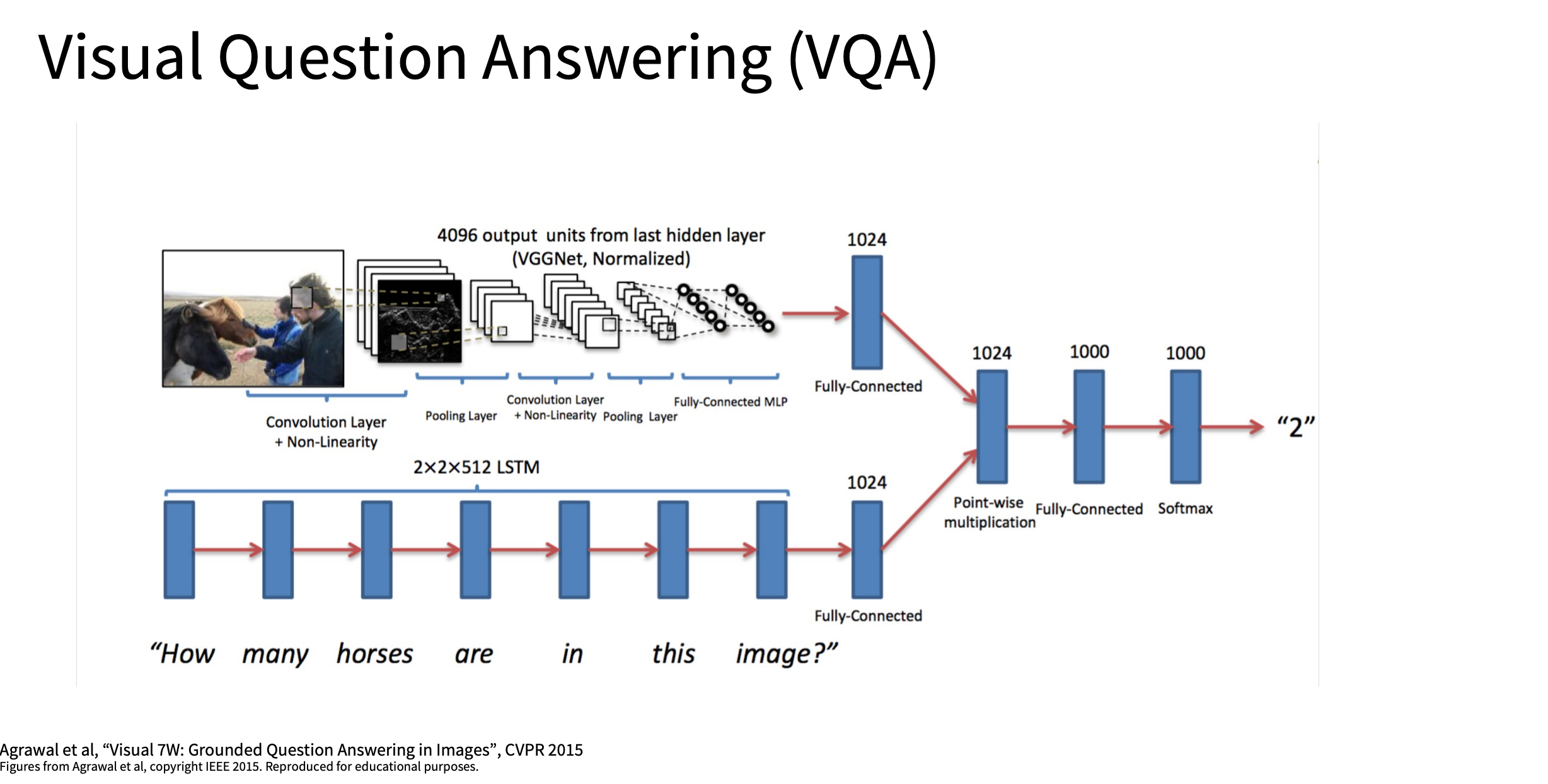 image.png
image.png
多模态应用
在 视觉问答(VQA) 或 多模态学习(Multimodal
Learning) 中,模型需要处理不同类型的数据,例如:
- 图像(Image):用 CNN 提取的图像特征向量。
- 文本(Text):用 RNN / Transformer
编码的问题向量。
为了让模型能够同时利用这两种信息,我们需要将它们组合起来,然后输入到后续的神经网络层进行处理。
组合不同输入的方法?
(1) 直接连接(Concatenation)
最简单的方法是直接拼接(Concatenate):
z = [v; q]
其中:
- v 是图像特征向量(由 CNN 提取)。
- q 是文本问题向量(由 RNN/Transformer 编码)。
- z 是拼接后的新向量,表示组合后的输入。
1
2
3
4
5
6
7
| import torch
v = torch.randn(1, 512)
q = torch.randn(1, 256)
z = torch.cat([v, q], dim=1)
|
(2) 乘法交互(Multiplicative Interaction)
除了简单拼接,有时候我们希望让两个向量之间产生更复杂的关系,可以使用乘法交互,例如:
- 逐元素乘法(Element-wise Multiplication)
z = v ⊙ q
- 这样可以增强输入之间的特定特征交互。
- 但是要求 v 和 q
具有相同的维度,否则不能直接相乘。
- 双线性变换(Bilinear Transformation)
z = vTWq
- 这里 W 是一个学习的权重矩阵,它让两个向量进行更复杂的交互。
- 优点:可以捕捉更复杂的关系。
- 缺点:计算量较大,可能导致过拟合。
示例代码(PyTorch):
1
2
3
4
5
6
|
z_mult = v * q
W = torch.randn(512, 256)
z_bilinear = v @ W @ q.T
|
RNN 反向传播的问题
ht = tanh (Whht − 1 + Wxxt)
梯度流
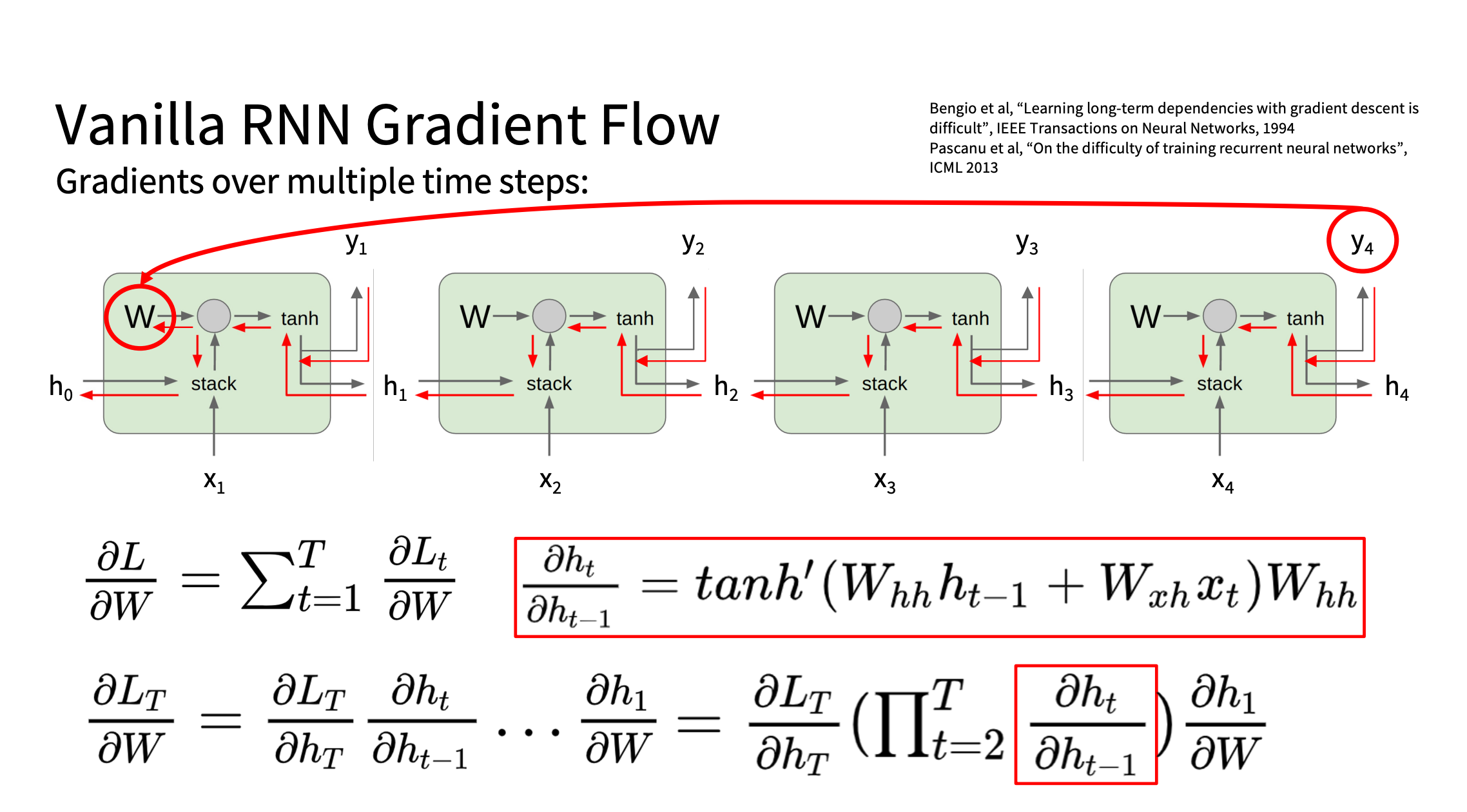 image.png
image.png
 不断左乘 WhT
也可能梯度爆炸或消失
不断左乘 WhT
也可能梯度爆炸或消失
或者这样看容易梯度消失
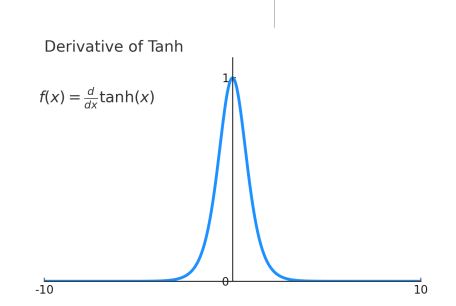 Almost always < 1
Almost always < 1
解决方案
- 梯度裁剪(Gradient Clipping)
- 在每次梯度更新时,将梯度限制在一个最大值(如 5)。
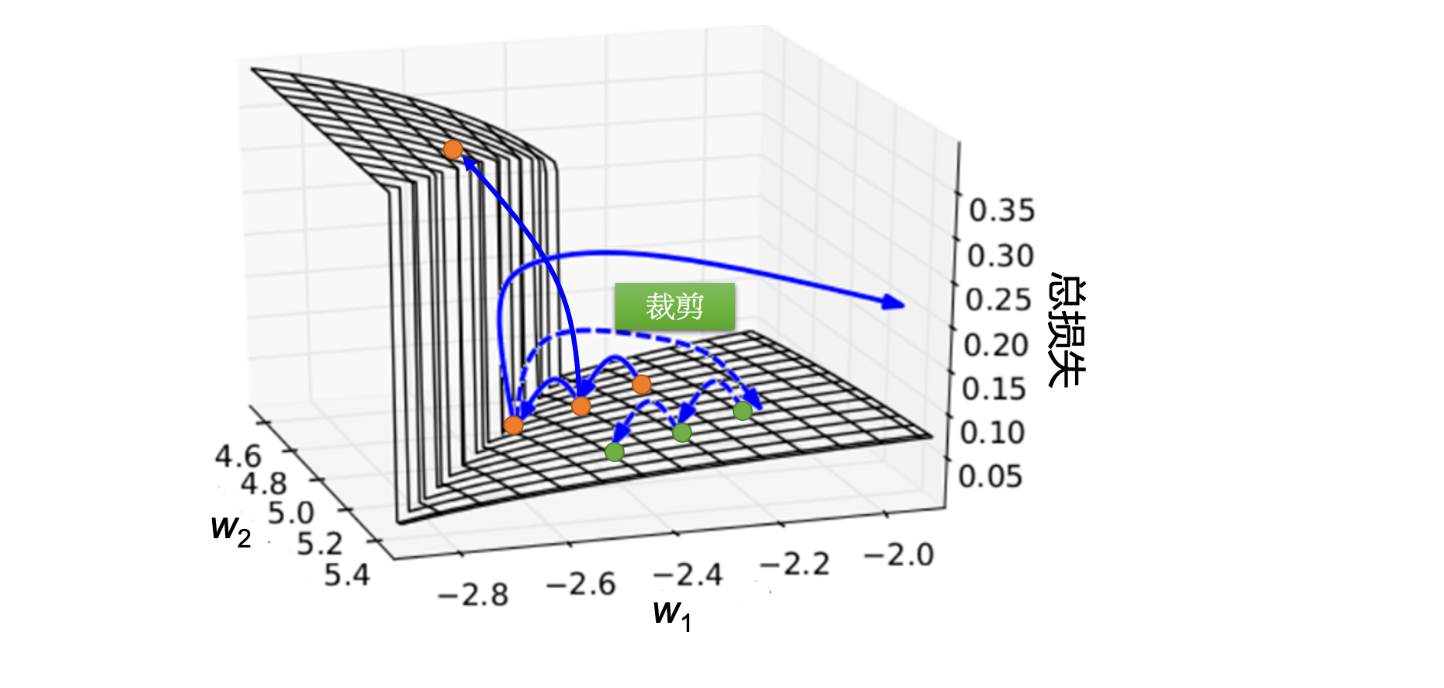 image.png
image.png
1
| torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5)
|
- 使用正则化
- 可以在训练过程中对权重矩阵 Wh
施加约束,比如:
- L2 正则化(权重衰减):避免权重值过大。
- Spectral Normalization(谱归一化):约束最大奇异值,使其接近
1。
- 使用 LSTM / GRU
- LSTM 和 GRU
通过门控机制(gates),让梯度可以更好地控制,不会完全消失或爆炸。
- LSTM
的长期记忆单元通过加法(不是乘法)存储信息,使其更稳定。
References